Raw Data¶
Tracking Data¶
Tracking data are the basis for linking your research-relevant variables. In addition to various demographic information, tracking data also provide information on how the interview is conducted. These data sets should be understood by you as initial data. You can use the tracking data to merge your research-relevant variables via the person and household numbers.
Dataset |
Label |
Format |
Identifier (ID) |
Additional Identifier |
|---|---|---|---|---|
ppath |
Individual Tracking File |
pid |
cid |
|
hpath |
Household Tracking File |
hid |
cid |
|
$pbrutto |
Gross Individual Data |
pid |
hid cid, hid_year |
|
$hbrutto |
Gross Household Data |
hid |
cid intid1 intid, hid_year |
|
hbrutto$$ |
Original gross population of a first wave sample |
hid |
cid, hid_year |
|
cov_brutto |
Gross Household Data SOEP-COV |
hid syear |
tranche |
RAW Data
ppath “Individual Tracking File” (wide): For all years since 1984, the PPATH dataset contains information on all persons who have ever lived in a SOEP household at the time of a survey (i.e., all respondents, but also children under 17 years of age and persons who have never given an interview). PPATH is important for the delimitation of the examination units (persons), especially for longitudinal analyses.
RAW Data
hpath “Household Tracking File” (wide): For all years since 1984, the HPATH dataset contains information on all households that have ever participated in the SOEP survey at any point in time. HPATH is important for the delimitation of the examination unit (household), especially for longitudinal analyses. HPATH is particularly suitable for household analyses and can be used for pre-selection of specific households.
RAW Data
$pbrutto “Gross Individual Data” (CS): $PBRUTTO covers all respondents who were successfully interviewed for the first time in wave $ or were contacted for the purpose of being interviewed again in wave $. The dataset provides gross cross-sectional information on all SOEP respondents’ interviews as well as their positions in the panel framework.
RAW Data
$hbrutto “Gross Household Data” (CS): $HBRUTTO covers all households that were successfully interviewed for the first time in wave $ or were contacted for the purpose of being interviewed again in wave $. The datasets provide gross cross-sectional information on all SOEP households’ interviews as well as their positions in the panel framework.
RAW Data
hbrutt$$ “Initial gross population (first wave)” (CS): The datasets HBRUTT$ contain field information on the first waves of (almost) all surveyed samples in the respective year, both for respondent and non-respondent households. Non-respondent households from a first wave can only be found in this dataset. All cross-sectional variables from HBRUTT$$ are used for HBRUTT.
RAW Data
cov_brutto “Gross Household Data SOEP-COV” (long): COV_BRUTTO contains the brutto information of SOEP-CoV study. This datset is associated with the 9 tranches of the SOEP-CoV in 2020, the SOEP-CoV wave in 2021 and COVID-19-special interviews 2020 from the IAB-BAMF-SOEP Survey of Refugees in Germany. More information about the project can be found online:
Original Data¶
These datasets contain the information provided by respondents. The contents of these variables are 1:1 the contents of the survey instruments. By searching the questionnaires, you can determine the exact wording of the question and any filtering.
Dataset |
Label |
Format |
Identifier (ID) |
Additional Identifier |
|---|---|---|---|---|
$p |
Data from individual questionnaire |
pid |
hid_year, syear, cid, intid, hid_year |
|
$pausl |
Migrant specific questions in the Individual Questionnaire |
pid |
hid, cid, hid_year |
|
$post |
Data from east specific questions in indivial questionnaire |
hid |
cid, intid, hid_year |
|
$h |
Data from household questionnaire |
hid |
syear, cid, intid, hid_year |
|
$housing |
Data on residential environment |
hid |
cis, syear |
|
$jugend |
Data from youth questionnaire for 16-17-year-olds |
pid |
hid, syear, cid, intid, hid_year |
|
$school |
Data from pre-teen questionnaire for 11-12-year-olds |
pid |
hid, syear, cid, intid, hid_year |
|
$school2 |
Data from early youth questionnaire for 13-14-year-olds |
pid |
hid, syear, cid, intid, hid_year |
|
$pluecke |
Data from individual catch-up questionnaire |
pid |
hid, cid, intid, hid_year |
|
ev |
First wealth module |
pid |
hid, syear, cid, hid_year |
|
$vp |
Data from deceased individual questionnaire |
pid |
hid, syear, cid, vpersnr, intid, hid_year |
|
$lela |
Data from biography questionnaire |
pid, syear |
hid, cid, intid, hid_year |
|
$biorki |
Infected with the coronavirus |
pid date |
cid hid tranche |
RAW Data
$post “Data on eastern germany from individual questionnaire” (CS):: The datasets $POST include the complete file of population and variables for the East German subsample in 1990 [GPOST] and the population-specific set of additional variables for East Germans in 1991 [HPOST].
RAW Data
$p “Data from individual questionnaire” (CS): The $P-files contain all variables of the individual questionnaire for the wave $. In addition, the individual-specific data of the samples IAB-SOEP Migration and IAB-BAMF-SOEP Survey of Refugees are integrated into the original $P dataset.
RAW Data 1984-1995
$pausl “Migrant specific data from individual questionnaire” (CS) The datasets $PAUSL contain population-specific sets of additional variables for foreign nationals from 1984 – 1995 for the subsamples A-D.
RAW Data
$h “Data from household questionnaire” (CS): The $H-files contain all questions of the household questionnaire.
RAW Data
housing$ “Data on residential environment” (CS): Information on the residential environment was obtained from the interviewers. They were asked to answer ten questions on the
residential environment for each household they worked with, regardless of whether an interview with the household could be completed or not.
RAW Data only 1990
$host “East specific questions from the Household questionnaire” (CS): The dataset $HOST includes the complete file of population and variables for the East German subsample in 1990 [GHOST].
RAW Data
$jugend “Data from youth questionnaire for 16-17-year-olds” (CS): Since 2000 (wave Q), respondents between the ages of 16 and 17 have received a separate biographical questionnaire with additional age-group-specific questions, for instance, about their relationship to their parents or about what they do in their free time.
RAW Data
$youth “Data from youth questionnaire for 12-17-year-olds” (CS): Since 2023 three questionnaires have been combined. “Pupils”, “Early-Youth” and “Youth”.
RAW Data
ev “First wealth module” (long): The dataset $EV contains information on assets, surveyed in 1988 [E] at the household level.
RAW Data
$school “Data from pre-teen questionnaire for 11-12-year-olds” (CS): Since 2014, the $SCHOOL files contain all variables from the “Pre-teen (Schülerinnen und Schüler)” questionnaire. The datasets provide variables about school, home, leisure time, health, self-perception and relationships with friends, siblings, and parents.
RAW Data
$school2 “Data from early youth questionnaire for 13-14-year-olds” (CS): Since 2016, the $SCHOOL2-files contain all variables from the “Early Youth (Frühe Jugend)” questionnaire. The datasets provide variables about self-perception, independence, school, leisure time or relationships with friends, siblings, and parents.
RAW Data
$pluecke “Data from individual catch-up questionnaire” (CS): Temporary drop-outs (“gaps”) can cause problems for longitudinal analysis. This is especially true for the employment and income data. That is why the SOEP tries to fill in at least some of the key missing information. $PLUECKE is a small questionnaire covering information on the year previous to which the drop-out occurred. This covers questions on job-related changes, employment history, income, education, and qualifications.
RAW Data
$vp “Data from deceased individual questionnaire” (CS): The $VP-files contain information about respondents who lost a relative in the previous year. It provides information about the deceased person and the respondent who reported the loss.
RAW Data
cov “SOEP-COV questionnaire” (long): COV contains the survey content of SOEP-CoV study. This datset is associated with the 9 tranches of the SOEP-CoV in 2020, the SOEP-CoV wave in 2021 and COVID-19-special interviews 2020 from the IAB-BAMF-SOEP Survey of Refugees in Germany. More information about the project can be found online:
RAW Data
$biorki “Infected with the coronavirus” (CS): Dataset of RKI-SOEP study. The dataset contains information about: “How many people have already been infected with the coronavirus, SARS-CoV-2? How many infections have gone undetected?” More information about the project can be found online
outdated
$p_mig “IAB-SOEP Migration Sample: Original individual questionnaire” (CS): The original data from the Sample M survey instrument can be found in the dataset $P_MIG, combining the individual and the biographical questionnaire. Since the current version, “v34”, the dataset has been fully integrated. The variables are also included in generated datasets. Variables equivalent to variables in the individual questionnaires for other samples are included in the dataset $P. Variables equivalent to variables in the biography questionnaires for other samples are included in the respective biography dataset (e.g., BIOMARSM). The comprehensively surveyed migration biography can be found in the new dataset MIGSPELL.
outdated
$p_refugees “IAB-BAMF-SOEP Survey of Refugees in Germany: Original Individual Questionnaire” (CS): The original data from the survey instruments used in Samples M3 and M4 can be found in original format in the dataset $P_REFUGEES, where the individual and the biographical questionnaires are combined. Since the current version, “v34”, the variables have been integrated in original or generated datasets. Variables equivalent to those in the individual questionnaire of other samples are included in the dataset $P. Also included in $P are all variables that are collected more than once but specific to the refugee questionnaire. Variables equivalent to those in the biographical questionnaires for other samples are included in the respective biographical datasets (e.g., BIOMARSM). The comprehensively surveyed migration biography can be found in the new dataset REFUGSPELL.
outdated
$h_refugees “Household questionnaire Refugee Sample” (CS): The $H_REFUGEES files contain all questions from the refugee household questionnaire. Since the current version, “v34”, the variables have been integrated into original or generated datasets.
RAW Data
$recruit “Pre-Recruitment” : The file of this short questionnaire contains data on the target persons willingness to participate and their availability, as well as a few content-related questions aimed at arousing the target persons’ interest in the survey.
Survey Data¶
These datasets contain information on survey methodology for SOEP-Core. The various datasets provide detailed exit information from respondents and household weighting factors that are needed for representative analysis.
Dataset |
Label |
Format |
Identifier (ID) |
Special Identifier |
|---|---|---|---|---|
phrf |
Weighting and staying probabilities |
pid |
cid |
|
hhrf |
Weighting and staying probabilities |
hid, cid |
hid_year |
|
exit |
Cumulative drop-outs |
pid |
cid, syear |
|
cirdef |
Randomized survey file |
cid |
||
cov_contact |
Contact Data SOEP-COV |
hid ContactDate |
tranche |
RAW Data
phrf “Weighting and staying probabilities” (wide): In the SOEP data, different weighting variables for cross-sectional as well as for different kinds of longitudinal weighting are set aside for each person in the PHRF file. The weighting variables can also be found in PPATHL.
RAW Data
hhrf “Weighting and staying probabilities” (wide): In the SOEP data, different weighting variables for cross-sectional as well as for different kinds of longitudinal weighting are assigned to each household in the HHRF file. The weighting variables can also be found in HL.
RAW Data
cirdef “Randomized survey file”: This dataset includes randomized groups of original sample households [rgroup] for selection of representative shares across all subsamples with full representation of any cross-sectional and longitudinal information (variables) at all levels (case, households, individuals, spells) for the entire SOEP population across all waves.
RAW Data
cov_contact “Contact Data SOEP-COV”: COV_CONTACT contains the contact information of SOEP-CoV study. This datset is associated with the 9 tranches of the SOEP-CoV in 2020, the SOEP-CoV wave in 2021 and COVID-19-special interviews 2020 from the IAB-BAMF-SOEP Survey of Refugees in Germany. More information about the project can be found online:
RAW Data
exit “Follow-up study [Verbleibstudie]”: The dataset EXIT delivers the results from the follow-up study [Verbleibstudie] conducted by Kantar Public (formerly: TNS Infratest) in 2008/2009. This study has been used to identify reasons for (demographic) dropouts. Deceased individuals identified through the follow-up study are included in the corresponding variables in PPATH/L [todjahr, todinfo].
Generated Data¶
The SOEP team has prepared these datasets in a research-friendly manner and has subjected them to additional plausibility checks and quality controls. They usually consist of several variables and different survey instruments and are described in the documentation provided. These datasets therefore cannot be assigned 1:1 to a survey instrument.
Dataset |
Label |
Format |
Identifier (ID) |
Additional Identifier |
|---|---|---|---|---|
$pgen |
Generated Individual Data |
pid |
hid, cid, hid_year |
|
$hgen |
Generated Household Data |
hid |
cid, hid_year |
|
$kind |
Data on children (from HH-Questionnaire) |
pid |
hid, cid, hid_year |
|
$pequiv |
Cross-national Equivalent File |
pid |
hid, syear, cid, hid_year |
|
$pkal |
Individual Calendar |
pid |
hid, cid, hid_year |
|
$pkalost |
Individual Calender |
pid |
hid, cid, hid_year |
|
bioregion |
Generated biographical information |
pid, syear |
cid |
|
bioresidrefinG |
Generated biographical information |
pid |
RAW Data
$pgen “Generated Individual Data” (CS): The $PGEN-files contain user friendly data on the individual level which are consolidated from different sources. The plausibility is validated longitudinally in many respects , therefore the data are superior in most situations compared to the data in $P. The file contains one row for each person (persnr is unique) with a completed individual or youth questionnaire.
RAW Data
$hgen “Generated Household Data” (CS): In order to minimize computing efforts for the user, the SOEP provides yearly status variables on household level. The $HGEN data provides a set of time-consistent variables generated from the SOEP household questionnaire. It only includes households that participated in the respective year.
RAW Data
$kind “Data on children (from HH-Questionnaire)” (CS): The variables from the annual $kind files are not based on answers provided by the children themselves, but by answers provided by the head of household. This data is re-aggregated on the person level and saved as child-specific entries in the file $kind. The annual $kind datasets also contain additional information on institutional care and school attendance for children and young people.
RAW Data
$pequiv “Cross-national Equivalent File” (CS): The $PEQUV-File is based on the Cross-National Equivalent File (CNEF) with extended income information for the SOEP. This file comprises not only the aggregated income figures provided in the CNEF but also further single income components.
RAW Data
$pkal “Individual Calendar” (CS): The $pkal datasets contain calendar variables from the individual questionnaire. The dataset includes the activity status on a monthly basis as well as the income status of a person.
RAW Data``1990-1991
$pkalost “Individual Calendar” (CS): PKALOST extends existing calendar information in PKAL. The file contains further current and retrospective calendar information for the East-German population in 1990 and 1991. These calender information include retrospective monthly data even for the time before unification.
RAW Data
bioregion “Generated biographical information” (long): A dataset on places in Germany that are of biographical importance to respondents (place of birth, first place of residence). Information about the federal state of these important places is includes in the EU data edition. More localized information (county or municipality) is only available remotely or on site.
RAW Data
bioresidrefinG “Generated biographical information” (long): A dataset on refugees’ place(s) of residence in Germany (Wohnorthistorie). Information about the federal state in which refugees reside is included in the EU data edition. More localized information (county or municipality) is only available remotely or on site.
Naming Convention of Data Sets and Variables¶
The following explanations only refer to the datasets of the subdirectory “raw” in your release file. There is no systematic variable naming for the long files above the subdirectory “raw”. To distinguish the multitude of datasets and variables, the SOEP uses systematic dataset and variable names for data in cross-sectional format. These names provide extensive information for data users. Example of a dataset name:
xp
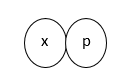
The first identifier of each dataset name is the wave identifier (“x”). It can contain one or two letters. .
Each wave or survey year can be assigned using a letter in the alphabet:
1984 |
1985 |
1986 |
1987 |
1988 |
1989 |
1990 |
1991 |
1992 |
1993 |
1994 |
1995 |
1996 |
1997 |
1998 |
1999 |
2000 |
a |
b |
c |
d |
e |
f |
g |
h |
i |
j |
k |
l |
m |
n |
o |
p |
q |
2001 |
2002 |
2003 |
2004 |
2005 |
2006 |
2007 |
2008 |
2009 |
2010 |
2011 |
2012 |
2013 |
2014 |
2015 |
2016 |
2017 |
r |
s |
t |
u |
v |
w |
x |
y |
z |
ba |
bb |
bc |
bd |
be |
bf |
bg |
bh |
2018 |
2019 |
2020 |
||||||||||||||
bi |
bj |
bk |
As can be seen from the table, the sample dataset “xp” contains survey information from the survey year 2007.
The second identifier of each dataset name is the abbreviation for the respective survey instrument or, for generated datasets, the name of the content (“p”).
h= Household
hbrutto= Household Gross
hgen= Generated Household Data
p= Individuals
pbrutto= Person Gross
p_mig= Migrants
pgen= Generated individual data
jugend = Youth (Ages 16-17)
school= Pre-teens (Ages 11-12)
vp= Deceased persons
luecke= Gap Questionnaire
hkind= Information for children from household questionnaire
pequiv= Cross National Equivalent File
pkal= Calendar
Further examples:
bah = Wave “ba” (Survey year 2010), Household datasets
bfschool= Wave “bf” (Survey year 2015), Pre-teen datasets
zhgen = Wave “z” (Survey year 2009), Generated household datasets
Variable names in the SOEPcore data files follow basic conventions: First, there are datasets with “speaking” variable names, where the variable name itself conveys something about the information stored in this variable. This is usally the case when the dataset is generated.
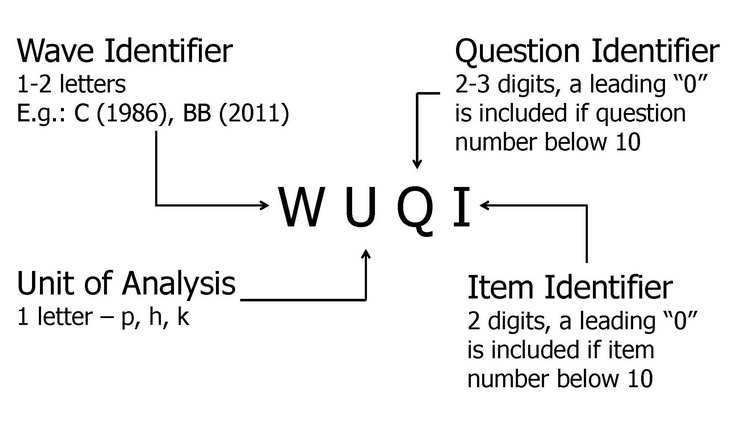
For the original datasets such as $H, $P, and $KIND, the variable names are set up “around” the unit of analysis (individual - “p”, household - “h”, and child - “k”) and show before this indicator the wave in which the data was collected and after it the reference where the question can be found in the original survey instrument (see Figure 9 for an overview).
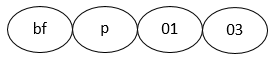
Example for a variable name: bfp0103
The first identifier of a variable name is the wave (i.e., “bf”) Every wave or rather every year can be assigned to a specific letter in the alphabet:
1984 |
1985 |
1986 |
1987 |
1988 |
1989 |
1990 |
1991 |
1992 |
1993 |
1994 |
1995 |
1996 |
1997 |
1998 |
1999 |
2000 |
a |
b |
c |
d |
e |
f |
g |
h |
i |
j |
k |
l |
m |
n |
o |
p |
q |
2001 |
2002 |
2003 |
2004 |
2005 |
2006 |
2007 |
2008 |
2009 |
2010 |
2011 |
2012 |
2013 |
2014 |
2015 |
2016 |
2017 |
r |
s |
t |
u |
v |
w |
x |
y |
z |
ba |
bb |
bc |
bd |
be |
bf |
bg |
bh |
2018 |
2019 |
2020 |
||||||||||||||
bi |
bj |
bk |
As can be seen from the table, the variable “bfp0103” contains information from the survey year 2015.
The second identifier of a variable is the abbreviation for the respective survey instrument or the type of information (“p”)
h = Household
hbrutto = Household gross
hgen = Generated household data
p = Individual data
pbrutto = Individual gross
p_mig = Individual migrants (M1 und M2)
pgen = Generated individual data
jugend = Youth (16-17-year-olds)
school = Pre-teens (11-12-year-olds)
vp = Deceased people
luecke = Gap Questionnaire
hkind = Information on children from the household questionnaire
pequiv = Cross-National Equivalent File
pkal = Calender
The third identifier in a variable name describes the question number (“01”) and a possible fourth identifier describes the position of the answer category (“03”).
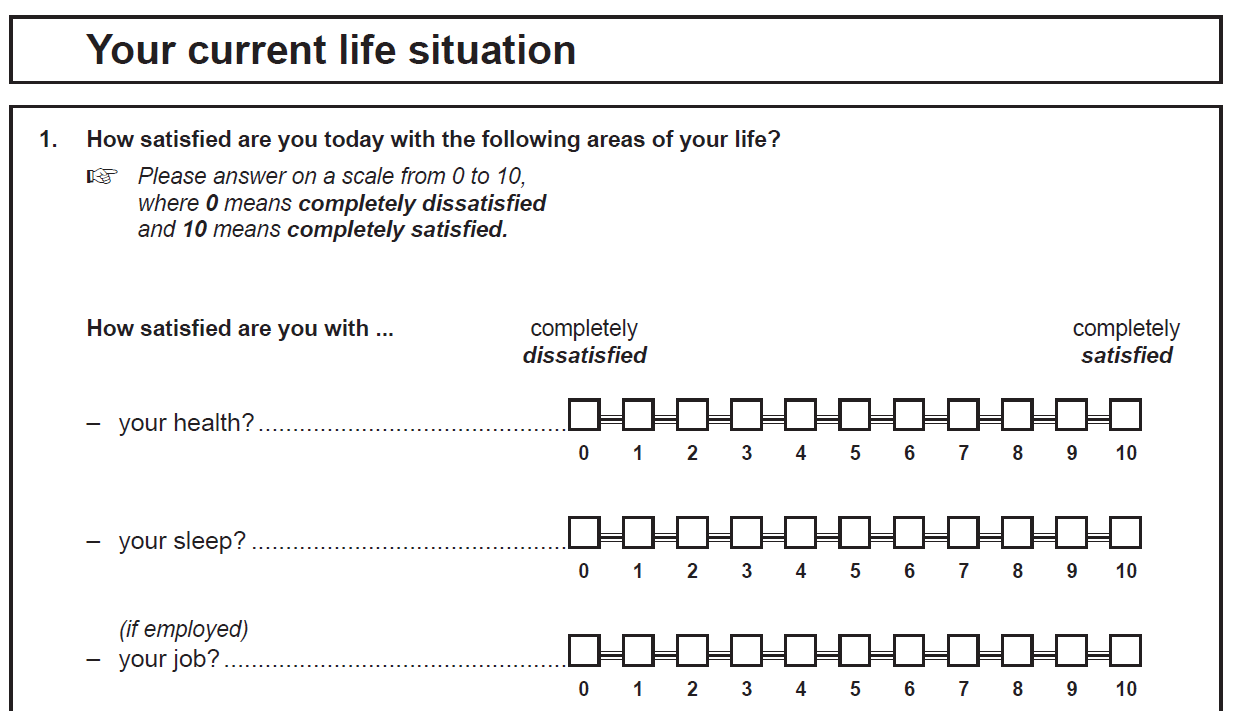
The variable “bfp0103” describes “satisfaction with work”. The variable was surveyed in 2015 (“bf”) and can be found in individual questionnaire (“p”), where it was part of the first question (“01”) and was listed as the third response category (“03”).
More examples: - ap06 = Wave “a” (survey year 1984), Individual Dataset, Question 6 - th1603 = Wave “t” (survey year 2003), Household Dataset, Question 16, Item 3 - lp10312= Wave “l” (survey year 1995), Individual Dataset, Question 3, Item 12 - bap15604 = Wave “ba” (survey year 2010), Individual Dataset, Question 156, Item 4
Since the data structure is becoming more complex every year, we extended the common variable naming convention WUQI starting with the wave “bh”(2017). Additionally, we provide our users with an “instrument” variable that contains all our survey instruments for each unit of analysis.
Extended Variable Naming Convention¶
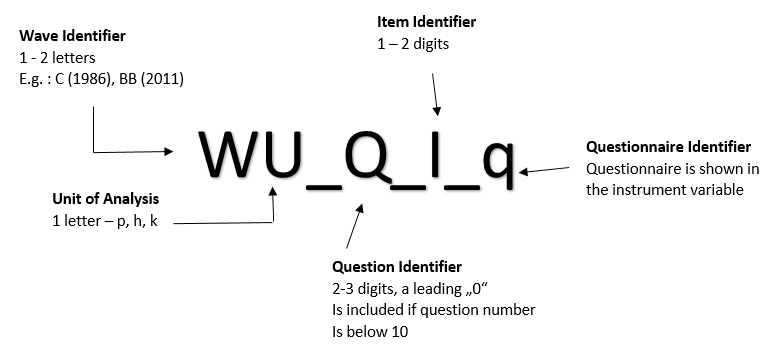
Note
The extended variable naming convention WU_Q_I_q has been used since version v.34 and is only used for datasets from wave bh onwards and only applicable to datasets $p, $h, $kind.
What’s new: We added underscores between the unit of analysis, question identifier, and item identifier to separate these visually. In addition, a questionnaire identifier was introduced, which is also separated by an underscore from the item. This new way of naming variables only comes into use if the survey instrument differs from the “original” instrument.
When working with the dataset in the wide format for the respective survey wave, it is generally not clear from the variable names which instruments were used to collect the information. This is not possible given the number of questionnaires. It is only possible to determine which questionnaires the variable was not surveyed in.
Main SOEP (A-L1 <- L2-3 <- N) <- Migrationsample (M1, M2) <- Refugee Sample (M3, M4) <- Refugee Sample (M5)
Due to our different samples in the SOEP, there are some sample groups that receive specific questions, such as the migrant sample that started in 2013. For this group, we created an extended individual questionnaire with migrant-specific questions and standard SOEP questions that are asked every year. If you want to know where variable var1 was collected, there are the following possibilities:
The metadata-based codebook answers the question, or you can use the following Stata command:
fre instrument if var1!=-5
Let`s take a look at the variable bhp109_01_q57
bh= Year 2017
P= Person questionnaire
109= Question 109
_01= First Item
_q57= ?
To know which questionnaire is the right one, look at the instrument variable.
Value |
Questionnaire |
|---|---|
50 |
2017 Individual Questionnaire (A-L1 ; PAPI) [soep-core-2017-pe] |
51 |
2017 Individual Questionnaire (A-L3 ; CAPI) [soep-core-2017-pe2] |
52 |
2017 Individual Questionnaire (L2-L3 ; CAWI) [soep-core-2017-pe3] |
53 |
2017 Individual Questionnaire (N; CAPI) [soep-core-2017-pe4] |
54 |
2017 Individual Questionnaire (M1-M2 Re-Surveyed; CAPI) [soep-core-2017-p-m12] |
55 |
2017 Questionnaire Individual-Biography (M1-M2 First-Surveyed; CAPI) [soep-core-2017-pb-m12-erst] |
56 |
2017 Questionnaire Individual-Biography (M3-M5 First-Surveyed; CAPI) [soep-core-2017-pb-m345-erst] |
57 |
2017 Questionnaire Individual-Biography (M3-M4 Re-Surveyed; CAPI) [soep-core-2017-pb-m34-wieder] |
58 |
2017 Biography Questionnaire (A-L1 First-Surveyed; PAPI) [soep-core-2017-ll] |
59 |
2017 Biography Questionnaire (A-L3; N First-Surveyed; CAPI) [soep-core-2017-ll2] |
The variable that can be used to identify the questionnaire can be found in the respective dataset. The value Q57 given in the example identifies the individual biography questionnaire for re-surveyed respondents in samples M3/M4 as the variable source. If you are now interested in the exact question in the questionnaire, open the individual biography questionnaire for refugees (re-surveyed), find question 109, and look at the first item. The variable bhp109_01_q57 was surveyed using the following question:
Q109: When did the integration course start?
|
Using the variable name and the instrument variable, you can easily identify the corresponding question in the corresponding questionnaire:
bhp109_01_q57
bh = Year 2017
P = Individual questionnaire
109 = Question 109
_01 = First Item
_q57 = 2017 Questionnaire Individual Biography (M3-M4 Re-Surveyed; CAPI) [soep-core-2017-pb-m34-wieder]
Last change: Apr 07, 2026