Datasets SOEP-Core¶
SOEP-Core contains a multitude of different datasets. An overview of the documentation for the different datasets can be found on our website, under Documentation of SOEP-Core.
To get an overview of the data types, a somewhat simplified categorization helps: There are Tracking Data and Survey Data files which describe the development of the sample, such that the user knows which individual or household was part of the interviewed sample in any given year. Then there are Original Data files, which contain the data from each year’s questionnaires without any changes except for very basic consistency checks. To help the user with the data, there also are Generated Data. These contain consistently coded variables across all waves with common names, such that the users can easily use this information when combining datasets across waves. The SOEP also provides various data on the respondent’s background, called biographical data. Biography data in general can conceptually be separated into biographical data which are unchanging (such as information on parent’s education, or data from the Mother-Child Questionnaires) and data which may be updated through changes in a respondent’s life (such as new children in the birth biography, or a job change in the job history). Some of the changing data are stored as Spell Data. For each spell there is a definition of the spell type, begin point, end point and the censoring status, indicating if a given employment or income spell is censored (left and/or right) or uncensored. One of the biggest assets of the SOEP data is their longitudinal nature, i.e., repeated observations of the same unit (individual or household) over time. That’s why we provide longitudinal datasets, such as PL or HL. Finally, there are some files which cannot be easily categorized - some are one-time datasets, some provide information about the interviewers, some about respondents outside of Germany.
There are two datasets which should be the building block of any analysis, as they allow users to define longitudinal populations very easily: PPATHL and HPATHL. HPATHL includes all households which have been interviewed successfully at least once. Similarly, PPATHL contains all individuals who have ever lived in a household that has participated in the SOEP, i.e., that has been captured in HPATHL, including non-respondents and children. Both data files contain one record per household or individual, respectively, with wave-specific variables for each year’s survey status. In addition to some time-invariant information (like gender, year of birth, migrant status), these files contain all necessary identifiers to combine other files with PPATHL and HPATHL. Although they provide essential information, PPATHL and HPATHL alone are of little use for actual analyses. The most often used sources for additional information in SOEP-Core are the cross-sectional data files provided in each survey year (or “wave”) or the datasets in the “long” Format.
The SOEP datasets can be viewed based on their content classification (Tracking Data, Original Data, Survey Data, Generated Data and Spell Data), the data structure (cross-sectional (cs), wide, long, spell) and also from the respondent’s perspective. From the respondent’s perspective, datasets can contain gross or net information. In addition, some datasets provide information only at the household level and others provide information at the individual level.
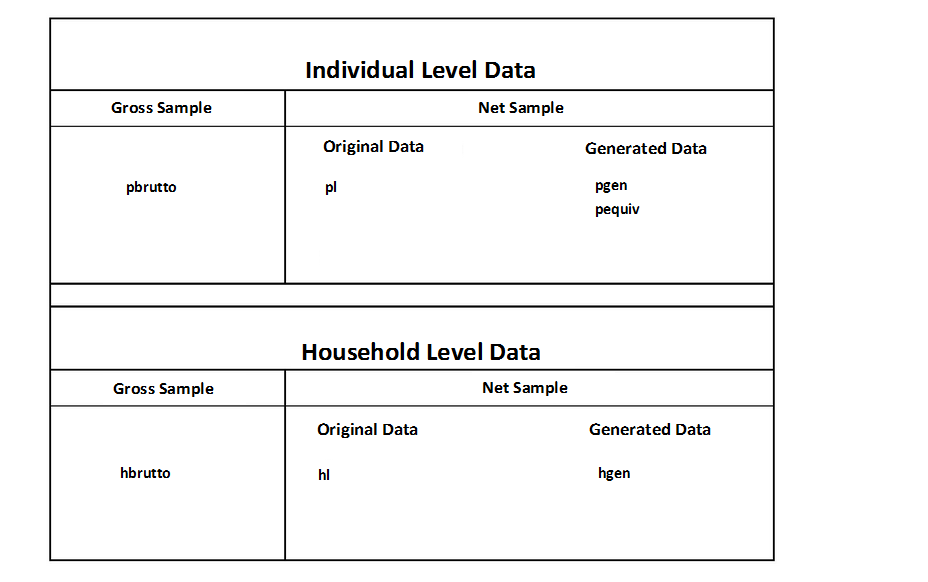
Gross information at household or individual level is provided to users in the datasets hbrutto, hbrutt and pbrutto. Content information collected from household or individual questionnaires, for example, is original data and is stored in HL and PL. The SOEP team generates data from these original data, which are generated from the many SOEP questionnaires. New generated and user-friendly datasets such as pgen are created from the components of PL.
Tracking Data¶
Tracking data are the basis for linking your research-relevant variables. In addition to various demographic information, tracking data also provide information on how the interview was conducted. These datasets should be understood as initial data that you can use to merge your research-relevant variables via the individual and household numbers.
Dataset |
Label |
Format |
Identifier (ID) |
Additional Identifier |
|---|---|---|---|---|
ppathl |
Individual Tracking File |
pid syear |
hid cid parid |
|
hpathl |
Household Tracking File |
hid syear |
cid |
|
pbrutto |
Gross Individual Data |
pid syear |
hid cid intid hhnrold |
|
hbrutto |
Gross Household Data |
hid syear |
cid intid1 intid |
|
hbrutt |
Initial gross population (first wave) |
hid syear |
cid |
|
instrumentation |
Data about the usage of the instruments |
hid pid pid2 instrument syear |
||
pbr_exit |
Cumulated Exit |
pid syear |
hid cid hnrold |
hpathl “Household Tracking File” (long): HPATHL consists of all waves of the raw datasets HPATH and HHRF. For all years since 1984, the HPATHL dataset contains information on all households that have ever participated in the SOEP survey at any point in time. HPATHL is important for the delimitation of the unit of investigation (household), especially in longitudinal analysis. HPATHL is useful particularly for household analysis and can be used for pre-selection of specific households.
ppathl “Individual Tracking File” (long): PPATHL consists of all waves of the raw datasets PPATH and PHRF. For all years since 1984, the PPATHL dataset contains information on all individuals who have ever lived in a SOEP household at the point in time of a survey (i.e., all respondents, but also children under 17 years of age and individuals who have never given an interview). PPATHL is important for the delimitation of the units of investigation (individuals), especially for longitudinal analysis. It contains one record for each individual and year a individual has been a member of a respondent household. It is keyed on pid and syear, the survey year identifier. It contains the Household ID, the unvarying individual characteristics, individual weights, as well as the response status for that individual in each wave.
pbrutto “Gross Individual Data” (long): PBRUTTO consists of all waves of the raw datasets $PBRUTTO. PBRUTTO covers all respondents who were either interviewed for the first time or contacted for the purpose of being interviewed again in a given wave. The dataset provides gross information on all SOEP respondents’ interviews as well as their positions in the panel framework.
hbrutto “Gross Household Data” (long): HBRUTTO consists of all waves of the raw datasets $HBRUTTO. HBRUTTO covers all households that were successfully interviewed for the first time in a wave or were contacted for the purpose of being interviewed again. The datasets provide gross information on all SOEP households’ interviews as well as their positions in the panel framework.
hbrutt “Initial gross population (first wave)” (long): The dataset HBRUTT contains field information on the first waves of all surveyed samples (except for samples C and D), both for respondent and non-respondent households. Non-respondent households from first waves can only be found in this dataset. For HBRUTT all cross-sectional variables from HBRUTT$$ are used.
instrumentation “Data about the usage of the instruments” (long): The instrumentation data set records at the individual level which survey instruments are intended for each person and what the respective realization status is. If the instrument contains information about another person (e.g. for children’s instruments), the number of the third person is also stored in the data record. This way, each line is uniquely identified by the household ID, person ID and instrument ID (hid, pid, instrument and (pid2)). Basis for the decision which instruments are provided is the realized household matrix. If this is not available for a household, the information from the general sample is used instead. Missing information (e.g., which person in the household is supposed to provide information about a child) are stored in the data set with the code -1.
Outdated
pbr_exit “Cumulated Exit” (long): The dataset pbr_exit is a supplement of pbrutto for individual dropouts. Individual dropouts are removed from the original pbrutto population, so that pbrutto covers all current household members. Pbr_exit contains the corresponding register information on individual dropouts from households. Now to find in PBRUTTO again
Original Data¶
These datasets contain respondents’ direct information. The contents of these variables mirror the contents of the survey instruments. By searching the questionnaires, you can determine the exact wording of the question and obtain possible filter guidance.
Dataset |
Label |
Format |
Identifier (ID) |
Additional Identifier |
|---|---|---|---|---|
pl |
Data from individual questionnaires |
pid, syear |
hid, cid, intid |
|
hl |
Data from household questionnaires |
hid, syear |
cid, intid |
|
biol |
Data from biography questionnaires |
pid, syear |
hid, cid, intid |
|
youthl |
Data from youth questionnaires for 16-17-year-olds |
pid, syear |
hid, cid, intid |
|
kidlong |
Data on children from household questionnaires |
pid, syear |
hid, cid |
|
childl |
Data from integrated parents via child questionnaires |
pid, pide, syear |
hid,cid |
|
housing |
Data on residential environment |
hid, syear |
cid |
|
more_docu |
Dataset on the Mentoring of Refugees (MORE) Project |
pid, syear |
hid, cid |
|
more_local |
Dataset on the Mentoring of Refugees (MORE) Project |
pid, syear |
hid, cid |
|
plueckel |
Data from individual catch-up questionnaires |
pid, syear |
hid, cid, intid |
|
abroad |
Data from questionnaire for individuals moved abroad |
pid, syear |
hid, cid |
|
vpl |
Data from deceased individual questionnaires |
vpid, syear |
hid, cid, intid |
pl “Data from individual questionnaire” (long): The PL dataset contains all waves of the $P datasets from SOEP-Core. In addition, the PL file includes all information of all waves of the datasets $POST and $PAUSL. This means that the PL dataset contains all information from the individual questionnaire for all waves. In addition, the individual-specific data from the IAB-SOEP Migration Survey and IAB-BAMF-SOEP Refugee Survey are integrated into the PL dataset.
Attention
For large datasets we recommend the use of Stata/MP or Stata/SE on a computer with an internal memory of 16GB. Users can still work with the data in Stata/IC or on less powerful computers, but some modifications allow users to work effectively with even the largest datasets while placing low demands on their hard- and software.
clear
global data = "\\hume\rdc-prod\complete\soep-core\soep.v35"
* Search all available pl variables on paneldata.org: https://paneldata.org/soep-core/data/pl
describe using "$data/pl.dta"
use pid hid cid syear plh0149-plh0151 using "$data/pl.dta"
hl “Data from household questionnaires” (long): HL contains all waves of the datasets $H from SOEP-Core. This means that the HL dataset includes all information of the household questionnaires. In addition, the household-specific data from the IAB-SOEP Migration Survey and IAB-BAMF-SOEP Refugee Survey are integrated into the original HL dataset.
biol “Data from biography questionnaires” (long): BIOL contains cumulated individual-level raw data from the biographical questionnaire and from wave-specific biographical modules of the individual questionnaire. BIOL is intended to be used in addition to the generated biographical files (by advanced users) to complete (or modify) generated biographical variables.
Outdated
jugendl “Data from youth questionnaires for 16-17-year-olds” (long): JUGENDL contains the waves q (2000) up to the current wave of $JUGEND in SOEP-Core. Since 2000 (wave Q), first-time respondents between the age of 16 and 17 have received a separate biographical questionnaire with additional age-group-specific questions, for instance, about their relationship to their parents or about what they do in their free time.
youthl “Data from youth questionnaire for 12-16-year-olds” (long): In 2023, the “Early Youth”, “Pupil”, and “Youth” questionnaires were consolidated into a single, integrated instrument using filter guidance to address age- and context-specific modules. The data structure has been updated accordingly. The new dataset YOUTHL contains all responses collected with the integrated youth questionnaire. In addition, relevant information from the former BIOPUPIL and JUGENDL datasets has been transferred into YOUTHL where appropriate. Both legacy datasets will remain available for reference and use in earlier waves but will no longer be updated as of 2023.
childl “Data from integrated parents via child questionnaires” (long): The new dataset childl replaces the formerly known bioagel dataset. childl represents the data from the parent-child questionnaires in long format, known from other SOEP Long datasets. The variable names correspond to the long variable naming scheme, including versions and harmonized variables. Before 2022, information was collected on specific cohorts. From 2022 on, information will be provided on every child between 0 and 11.
housing “Data on residential environment” (long): As in the main study, information on the residential environment was also obtained from the interviewers. They were asked to answer ten questions on the residential environment for each household they worked with, regardless of whether an interview with the household could be completed or not. If the household lived in shared accommodation for refugees, additional questions about the accommodation were asked at the end of the interview with the head of household.
MORE_Docu “Dataset on the Mentoring of Refugees Projekt”: A dataset on the Mentoring of Refugees (MORE) project. Carried out in partnership with Start with a Friend (SWAF), this project aimed at bringing refugees and locals together to form friendships. This dataset contains information on German contacts provided to refugees. Information about the federal state of the SWAF location is includes in the EU data edition. More localized information (county or municipality) is only available remotely or on site.
screenigl : Dataset to determine which version of the individual questionnaire the respondent should receive. It clarifies wether the respondent has a migration background or not, or if the respondent is identified as a person with refugee background. Therefor the country and area of origin is collected as well.
MORE_Local “Dataset on the Mentoring of Refugees Projekt”: A new dataset on the Mentoring of Refugees (MORE) project. Carried out in partnership with Start with a Friend (SWAF), this project aimed at bringing refugees and locals together to form friendships. This dataset contains information from the surveys of the locals in the project.
plueckel “Data from individual catch-up questionnaires” (long): The PLUECKEL dataset contains all waves of the $PLUECKE datasets in SOEP-Core. Temporary drop-outs (“gaps”) can cause problems for longitudinal analyses. This has especially negative consequences for the employment and income data. That is why the SOEP tries to fill in at least some of the key missing information. The questionnaire Catch-up Individual is a small questionnaire covering information on the year previous to which the temporary drop-out occurred. It covers questions on job-related changes, employment calendar, income, education, and qualifications.
abroad “Data from questionnaires for individuals moved abroad” (long): With the pilot study “Life outside Germany” in 2008, the longitudinal SOEP study ventured into completely uncharted methodological territory by attempting to locate the addresses of former SOEP respondents who have since moved abroad and to survey these individuals with the help of a specially developed written questionnaire on the reasons for their move. The project was discontinued due to insufficient case numbers in 2014.
vpl “Questionnaire on the deceased individual” (long): The VPL dataset contains all waves of the $VP datasets of SOEP-Core. The VPL file contains information about respondents who lost a relative in the previous year. It provides information about the deceased individual and the respondent who reported the death.
selfempl “Questionnaire on self-employment”: The new dataset selfempl contains data from supplementary surveys conducted among self-employed individuals participating in SOEP-Core. The data were collected as part of the INNOMSME and SOEP-LEE2 projects. Currently, the dataset comprises two survey waves, 2020 and 2022, and covers topics related to the business of the self-employed, management activities, and their attitudes towards self-employment. More information about the data is available on the homepage of the RDC SOEP .
Survey Data¶
These datasets contain information on survey methodologies used in SOEP-Core. The various datasets contain detailed exit information provided by respondents and the household weighting factors that users need for representative analysis.
Dataset |
Label |
Format |
Identifier (ID) |
Special Identifier |
|---|---|---|---|---|
design |
Survey design |
cid |
intid |
|
pbr_hhch |
PBR_HHCH |
pid, syear |
hid, cid, pnralt, pnrneu, hhnrold |
design “Survey design”: The dataset DESIGN provides information on the stratified sampling of the SOEP in the form of two variables. The variable STRAT identifies each of the discrete sampling groups described above. Altogether, the SOEP consists of 40 strata: one stratum in sample A, twenty-seven in sample B, one in sample C, three in sample D, one in sample E, two in sample F, four in sample G, and one in sample H. Each of these strata have unique inclusion probabilities. The variable design contains the inverse of this probability, i.e., the design weight.
pbr_hhch “PBR_HHCH”: The dataset pbr_hhch is a subfile of pbrutto that was used from 1984 to 2009 to identify individuals from households that underwent split-offs in subsamples A-H.
Generated Data¶
The SOEP team has prepared these datasets for easy use and subjects them to additional plausibility checks and quality controls prior to data release. In most cases, they consist of several variables and different survey instruments and are described in the documentation provided. As a result, these datasets cannot be assigned 1:1 to a single survey instrument.
Dataset |
Label |
Format |
Identifier (ID) |
Additional Identifier |
|---|---|---|---|---|
pgen |
Generated individual data |
pid, syear |
hid, cid, pgpartnr |
|
hgen |
Generated household data |
hid, syear |
cid |
|
bioagel |
Generated biographical information |
pid, syear, persnre |
hid, cid, |
|
biopupil |
Generated biographical information |
pid, syear |
hid, cid |
|
kidlong |
Data on children |
pid, syear |
hid, cid |
|
pequiv |
Cross National Equivalent File |
pid, syear |
hid, cid |
|
biobirth |
Generated biographical information |
pid |
cid, kidpnr01-kidpnr15 |
|
bioedu |
Generated biographical information |
pid |
cid |
|
bioimmig |
Generated biographical information |
pid, syear |
hid, cid |
|
biojob |
Generated biographical information |
pid |
cid |
|
bioparen |
Generated biographical information |
pid |
cid, fnr, mnr |
|
biosib |
Generated biographical information |
pid |
cid, sibpnr1-sibpnr11 |
|
biotwin |
Generated biographical information |
pid |
cid, pnrtwin, pnrtrip, pnrquad |
|
camces |
Highest educational qualification, migrants sample M1 and M2 |
pid |
hid, syear, cid |
|
cogdj |
Data on cognitive tests (Youth) |
pid |
syear, cid |
|
cognit |
Data on cognitive potential |
pid |
syear, cid, intid |
|
cog_refu |
Data on cognitive tests (Refugees) |
pid |
syear, cid, hid |
|
gkal |
Generated calender data |
pid, syear |
hid, cid |
|
gripstr |
Grip Strength Measures |
pid, syear |
cid, intid |
|
hconsum |
Household Consumption Module |
hid |
syear, cid |
|
health |
Data on health indicators |
pid, syear |
cid |
|
hwealth |
Wealth module |
hid, syear |
cid |
|
interviewer |
Data on the SOEP interviewer |
intid, syear |
cid |
|
lkal |
Generated calender data |
pid, syear |
hid, cid |
|
mihinc |
Multiple imputed data on monthly household income |
hid, syear |
cid |
|
pflege |
Persons needing care within the household |
pid, syear |
cid |
|
pkal |
Individual calendar |
pid, syear |
hid, cid |
|
pwealth |
Wealth module |
pid, syear |
hid |
|
timepref |
Experiment on time preferences |
pid |
hid, syear, cid |
|
trust |
Experiment on trust |
pid |
hid, syear, cid |
pgen “Generated individual data” (long): PGEN contains all waves of the $PGEN datasets in SOEP-Core. The PGEN-file contains user-friendly data on the individual level that are consolidated from different sources. The plausibility is validated longitudinally in many respects, making the data superior to those in PL in most situations. The file contains one row for each individual (pid is unique) with a completed individual or youth questionnaire.
hgen “Generated household data” (long): HGEN contains all waves of the $HGEN datasets in SOEP-Core. In order to minimize computational effort for the user, the SOEP provides yearly status variables on the household level. The HGEN data provide a set of time-invariant variables generated from the SOEP household questionnaire. They only include households that participated in the respective year.
Outdated
bioagel “Generated biographical information” (long): The BIOAGEL data files are generated using information collected in the “Mother & Child” and “Parent” questionnaires. BIOAGEL is now provided in one dataset. Current data concerning Parents and Children is available in the childl dataset.
Outdated
biopupil “Generated biographical information” (long): The BIOPUPIL data files are generated using information collected in the “Pre-Teen” and “Early-Youth” questionnaires. BIOPUPIL is provided in one dataset. Current data concerning Pre-Teen and Early-Youth population is available in the youthl dataset
kidlong “Data on children” (long): The variables stored in the KIDLONG file are based on the information collected annually and contained in the wave-specific $KIND files. The relevant information is not provided by children themselves but is obtained from answers to questions in the household questionnaire provided by the respondent within the household (usually the head of the household). This data is reaggregated at the individual level and stored as child-specific entries in the file $KIND.
pequiv “Cross-National Equivalent File” (long): PEQUIV contains all waves of the $PEQUIV datasets in SOEP-Core. The PEQUV-File is based on the Cross-National Equivalent File (CNEF) with extended income information for the SOEP. This file comprises not only the aggregated income figures from CNEF but also additional separate income components.
pkal “Data from the monthly calendar from the individual questionnaire” (long): PKAL contains all waves of the $PKAL datasets in SOEP-Core. The PKAL datasets contain calendar variables from the individual questionnaire. The dataset includes the individual’s employment or educational status on a monthly basis as well as the individual’ income status.
biobirth “Generated biographical information” (wide): The file BIOBIRTH provides information on fertility histories of adult respondents in the SOEP. Up to 2014 (version 30, wave BD), the data were stored in two separate files: BIOBIRTH containing female fertility histories, and BIOBRTHM providing male fertility histories. Fertility histories in BIOBIRTH provide information on every woman (as well as every man with panel entry since 2001) who has ever completed at least one SOEP interview.
Outdated
bioedu “Generated biographical information” (long time constant): The SOEP contains a broad range of variables on early childhood education and care, educational participation, educational degrees, and related topics. The BIOEDU dataset is designed to provide ready-made variables on educational transitions and related topics for use in longitudinal analysis.
bioimmig “Generated biographical information” (long): The variables contained in BIOIMMIG relate to foreigners in (and migrants to) Germany. Questions deal with the desire to return to the home country, the presence of relatives in the home country, reasons for coming to Germany, and conditions upon initial arrival in Germany.
Outdated
biojob “Generated biographical information” (long time constant): The purpose of BIOJOB is to provide a file that offers the user convenient access to biographical information on past job activities. BIOJOB consists of generated variables as well as plain questionnaire information. Up to now, all but two variables in BIOJOB are time-invariant. Information on occupational changes and on the age at the most recent change of occupation refer to the date of the respondent’s biography interview.
bioparen “Generated biographical information” (long time constant): The dataset BIOPAREN contains biographical entries on the parents’ and respondent’s background. The information in BIOPAREN is obtained from two sources: from proxy entries by children on their parents in the biography questionnaire and youth questionnaire, and from direct entries by parents when the respondent lives in the same household as the parents. Please note that BIOPAREN focuses on the social parent. Biological parent identifiers can be found in BIOBIRTH.
Outdated
biosib “Generated biographical information” (wide): BIOSIB provides information on siblings living within SOEP households. The dataset contains the individual identifiers of all siblings in a SOEP household. It includes information on the individual sibling’s sex, year of birth, number of siblings, position in birth order, and relationship between siblings.
Outdated
biotwin “Generated biographical information” (wide): The file BIOTWIN contains all twins that were ever identified within the SOEP. To be classified as a twin, a individual is required to have exactly the same age as his or her sibling (year & month of birth), have a relationship to the head of the household that indicates that he or her and a second individuals are siblings, and have the same mother (as far as a pointer to the mother is available). Furthermore, it is not only twins that are recorded in the BIOTWIN dataset, but also triplets or quadruple siblings.
camces “Highest educational qualification, migrant samples M1 and M2” (CS): The CAMCES-File provides information about computer-assisted measurement and coding of educational qualifications in surveys.
cogdj “Data from cognitive tests (Youth)” (CS): In SOEP 2006, a separate questionnaire with cognitive tests for adolescents was used for the first time: “Lust auf DJ”. The acronym “DJ” stands for “Denksport und Jugend” (mind sports and youth)”, but it was named for its more common association with “disc jockey”. The questionnaire “Lust auf DJ” was created for all respondents aged 16-17.
cognit “Data on cognitive potential” (long): In the 2006 survey year, for the first time, short cognitive tests were carried out with a subsample of the SOEP. The goal was to employ a robust set of instruments that could be administered easily by trained interviewers within just a few minutes. COGNIT06 provides the aggregated sum scores (total values for three time packages, so-called “parcels” of 30, 60 and 90 seconds).
cog_refu “Data on cognitive tests (refugees)” (CS): The dataset contains sum scores for two competence measurements (previous school knowledge and basic cognitive skills) of youths born in 2000, 2003 and 2005 surveyed in 2017.
gripstr “Measures of grip strength (left and right hand)” (long): The data on grip strength from the survey year 2012 is now included in the GRIPSTR dataset.
hconsum “HH consumption module” (CS)“: We were faced with three methodological challenges in generating the final consumption data. First, due to the design of the consumption module, inconsistent answers arose between the amounts give for monthly and annual consumption. Second, there was the common problem of missing data, here in particular item nonresponse. And third, consumption data are usually blurred by heaping. For researchers who do not want their consumption variables to include changes from all steps of data preparation, the new dataset “HCONSUM” contains not only the prepared consumption variables but also flag variables providing researchers the opportunity to select individual solutions.
health “Data on health indicators” (long): Starting in 2002, the SOEP health module in the individual questionnaire has been revised and replicated at two-year intervals. In the HEALTH file, users find, for instance, the generated variables on height and weight with imputation flags and a user-friendly longitudinal checked generated variable for Body Mass Index (BMI).
hwealth “Wealth module” (long): The generated SOEP wealth data is stored in two separate data files called PWEALTH for information at the individual level and HWEALTH for correspondingly aggregated data at the household level. HWEALTH contains all information on the household level; it is purely the result of aggregating the individual-level information in PWEALTH. However, for all individuals with valid household-level information who did not respond to the individual questionnaire (partial unit non-response), imputations have been carried out and the results are included in HWEALTH.
interviewer “Data on the SOEP interviewer” (long): The SOEP aims not only to collect high-quality data on the living conditions and well-being of households, but also to provide a valuable empirical source for survey research. The INTERVIEWER file provides users with easy access to all available longitudinal information on the SOEP interviewers.
mihinc “Multiple imputed data on monthly household income” (long): The dataset MIHINC contains the complete imputation results and is available separately. To be compatible with methods for analyzing multiply imputed data, MIHINC is constructed in the “stacked” or MIM data format. It contains the following variables: HHNRAKT, SVYYEAR, MJ, MI, IHINC and IMPFLAG. Since 1995 for every survey household in all survey years, there are ten imputed values for current household income.
pflege “Persons needing care within the household” (long): Since wave B (1985), the SOEP household questionnaire includes questions on household members in need of care. In order to support individual-level analysis, this information has been restructured and is stored in the cumulative file PFLEGE.
pwealth “Wealth module” (long): For the first time in 2002, the individual questionnaire included a special module focusing on wealth. It included questions on seven different wealth components: owner-occupied property (including debt), other property (including debt), financial assets, private pensions (including life insurance and building savings contracts), business assets, tangible assets, and consumer credit. The generated SOEP wealth data are stored in two separate data files called PWEALTH for information at the individual level and HWEALTH for correspondingly aggregated data at the household level. Wealth-related variable names in the file PWEALTH consist of six digits. The first digit tells the user which wealth component is referred to, and the second to sixth digits provide more detailed information about possible filter information, the personal share, the gross amount, and the amount of any outstanding debt. In principle, a digit is coded “1” if a given variable does indeed contain this specific piece of information and “0” otherwise. The wealth information in the SOEP questionnaire is surveyed at the individual level and thus also imputed or edited at the individual level (although checked against household information for consistency).
timepref “Experiment on time preferences” (CS): Following the behavioral experiment on trust and trustworthiness carried out in the 2003, 2004, and 2005 SOEP surveys, the experiment “time preferences” was run in 2006. In this experiment on economic behavior, respondents were asked to decide how they would want to receive €200 in prize money: if they would want to receive it immediately by check or if they would want to wait and receive a larger amount later, that is, with interest.
trust “Experiment on trust” (long): The economic behavior experiment on trust and trustworthiness from survey years 2003, 2004, and 2005 served to measure trust based on an investment game, a one-off game for two players who interact anonymously. The first player receives a credit of ten points and can overwrite any number of points of the second player. Each overwritten point is doubled. The second player also receives a credit of ten points. After receiving the (doubled) points from the first player, the second player decides how much of her own credit she will transfer to the first player (zero to ten points). As with the first transfer, the recipient’s points are doubled. After the decision of the second player, the game ends and the other players are paid (one point corresponds to one euro, the total is paid by check a few days later). The trust dataset thus contains the information from all three waves in which the behavioral experiment was conducted.
gkal “Calender information” (long): Contains individual-level generated data by transforming the calendar information of the individual catch-up questionnaires in longitutional format since 2021, including explicit variables for each month.
lkal “Calender information” (long): Contains individual-level generated data by transforming the calendar information of the biography questionnaires in longitutional format since 2021, including explicit variables for each month.
Spell Data¶
Spell, duration, and event history data are used frequently in the social sciences. In the strict sense of the word, spell data are about time periods with a defined start and end. General information about the data structure of spell data can be found in the chapter Data Structure in Spell Format (spell)
Working with spell data:
Working with spell data (pdf):
Working with spell data (do-files):
How to generate spell data from data in wide format: Based on the migration biographies in the IAB-SOEP Migration Sample:
Dataset |
Label |
Format |
Identifier (ID) |
Additional Identifier |
|---|---|---|---|---|
artkalen |
Spell data from the activity calendar |
pid |
cid |
|
biocouplm |
Generated biographical information |
pid |
cid, coupid |
|
biocouply |
Generated biographical information |
pid |
cid |
|
biomarsm |
Generated biographical information |
pid |
cid |
|
biomarsy |
Generated biographical information |
pid |
cid |
|
einkalen |
[deprecated] Spell data on income |
pid |
cid |
|
lifespell |
Spell Information on the pre- and post-survey history of SOEP respondents |
pid |
cid |
|
migspell |
Migration history |
pid |
cid |
|
pbiospe |
Generated biographical information |
pid |
cid |
|
refugspell |
Migration history |
pid |
cid |
|
sozkalen |
[deprecated] Spell data on social benefits |
hid, cid |
artkalen “Spell data from the activity calendar” (long): The ARTKALEN contains spells (monthly) for events starting in January 1983. This is in contrast to PBIOSPE, where spells were in yearly durations, and events previous to 1983 were included. The information on activity status is collected on a monthly basis in the yearly individual questionnaire and stored in the file ARTKALEN.
biocouplm “Generated biographical information” (long): With the BIOCOUPLM the SOEP provides consistent and continuous partnership histories for nearly all adult respondents. BIOCOUPLM is built on the prospective information at the time of each interview. The relationsship histories are collected on a monthly basis from all adult SOEP participants since their entry into the SOEP.
biocouply “Generated biographical information” (long): With the BIOCOUPLY, the SOEP provides consistent and continuous partnership histories for nearly all adult respondents. BIOCOUPLY is built on retrospective and prospective information at the time of each interview. The relationship histories are provided on an annual basis.
biomarsm “Generated biographical information” (long): With BIOMARSM the SOEP provides consistent and continuous marital histories for nearly all adult respondents. BIOMARSM is built on the prospective information at the time of each interview. The martial histories are collected on a monthly basis from all adult SOEP participants since their entry into the SOEP.
biomarsy “Generated biographical information” (long): With BIOMARSY the SOEP provides consistent and continuous marital histories for nearly all adult respondents. BIOMARSY is built on retrospective and prospective information at the time of each interview. The marital histories are provided on an annual basis.
lifespell “Spell information on the pre- and post-survey history of SOEP respondents” The SOEP team regularly conducts follow-up studies to relocate attritors. These studies draw on official register data and allow us to determine whether a individual is still living in Germany, is deceased, or has moved abroad since the last SOEP interview. The information is combined in a spell file LIFESPELL. This dataset reports all available information on the pre- and post-survey history of all individuals who have ever been a member of a SOEP household.
Outdated
migspell “Migration history” (long): MIGSPELL is derived from the migration biographies, which are collected from each new respondent of the IAB-SOEP migration samples M1 and M2. It contains data on moves by foreign-born migrants as well as on stays abroad by German-born respondents.
pbiospe “Generated biographical information” (long): The spell file PBIOSPE is based on the information on activity status over the life course, which is collected as a matrix from every respondent who completes the biographical questionnaire. The observations start at the age of 15 and end at the current age (up to age 65). To update ongoing employment information in PBIOSPE, information from the yearly individual questionnaire is also used.
Outdated
refugspell “Migration history” (long): For migration biographies in the refugee samples, we created the spell dataset REFUGSPELL. The variables in MIGSPELL and REFUGSPELL are derived from different instruments and only partially overlap. The data structure allows the dataset to be linked with MIGSPELL if desired.
Outdated
sozkalen “Spell data on social benefits“: The file SOZKALEN provides spell data on households receiving social assistance, defining the beginning, end, and censoring status of any period of receiving 3 different types of assistance. This file is set up using information from the calendar that is collected for the previous year (between 1992-2000). Thus, it contains information on a monthly basis.
Last change: Apr 07, 2026