Working with information on instruments (INSTRUMENTATION)¶
Since 2021 specific information on instruments are avaiable in the dataset INSTRUMENTATION. The instrument dataset captures information at the individual level about the intended survey instruments and their respective status of implementation.
Identifiers of this Dataset
Never Changing Person ID of the Respondent (pid)
ID Household (hid)
Instrument which was or had to be answered (instrument)
Never Changing Person ID of the person about whom information was provided in the survey (pid2)
Survey Year (syear)
Other constant information to the respondent
Case ID (cid)
ID Household in 2021 (hid_2021)
Sample Identificator (sample1)
Methodological Information on Instruments:
Survey Mode (mode)
Processing Status (status)
Interviewer ID (intid)
Datatype to which the instrument mainly belongs (datatype)
Start of the interview (start)
End of the interview (end)
Switch in the survey mode (switchwish)
Duration of the interview (duration)
Administration (conduct)
Language at the beginning of the interview (start_language)
Language at the end of the interview (end_language)
Viewport (JavaScript) first questionaire page height (viewph_first)
Viewport (JavaScript) first questionaire page width (viewpb_first)
Viewport (JavaScript) last questionaire page height (viewph_last)
Viewport (JavaScript) last questionaire page width (viewpb_last))
Context Information for the Survey Situation:
Presence during completion: Father/Mother (present5)
Presence during completion: Spouse/Partner (present1)
Presence during completion: other household member (present2)
Presence during completion: other non-household person (present3)
Presence during completion: Nobody (present4)
Survey distractions (distract)
Device: stationary computer (device_01)
Device: Laptop/Notebook (device_02)
Device: Tablet (device_03)
Device: Smartphone (device_04)
Device: Other (device_05)
Destriction of the other device used (device_05_open)
Location of survey administration (location)
Description of the location of survey administration (location_open)
Feedback on the questionaire (feedback)
Quality Indicators
There are different indicators for quality checks of the interviews: pbrutto, valid and improper.
Component of the adjusted personal gross sample (pbrutto)
Survey validity (valid)
Assessment of the realism of the household interview from the interviewer (evalhh)
Open remark from the interviewer (evalopenhh)
Assessment of the realism of the personal interview from the interviewer (evalp)
Open remark from the interviewer (evalopenp)
The variable ‘pbrutto’ indicates whether the respondent is part of the adjusted gross sample. ‘valid’ indicates whether the interview can be considered valid [1] or not valid [0]. An interview is scored as invalid if it is decided, based on interviewer checks performed, that an interview was conducted improperly. Further, an interview is scored as invalid if it is identified based on data-based checks that the wrong person was interviewed. Furthermore, for terminated interviews, only [1] is indicated if a specific question was reached. The variable is validated by the survey institute.
The dataset is explained in more detail in the following documentation:
Documentation instrumentation:
Create an exercise path with four subfolders:

Example:
H:/material/exercises/do
H:/material/exercises/log
H:/material/exercises/output
H:/material/exercises/temp
These are used to store your script, log files, datasets and temporary datasets. Open an empty do-file and define your paths with globals:
1***********************************************
2* Set relative paths to the working directory
3***********************************************
4global AVZ "H:/material/exercises"
5global MY_IN_PATH "//hume/rdc-prod/distribution/soep-core/soep.v38/eu/Stata/soepdata/"
6global MY_DO_FILES "$AVZ/do/"
7global MY_LOG_OUT "$AVZ/log/"
8global MY_OUT_DATA "$AVZ/output/"
9global MY_OUT_TEMP "$AVZ/temp/"
The global „AVZ“ defines the main path. The main paths are subdivided using the globals “MY_IN_PATH”, “MY_DO_FILES”, “MY_LOG_OUT”, “MY_OUT_DATA”, “MY_OUT_TEMP”. The global “MY_IN_PATH” contains the path to the data you ordered.
Based on the data in INSTRUMENTATION, answer the following questions:
1. Look at the household with the household ID (hid) 3140813
a) Which instruments did the household (hid=3140813) had to answer? Which do they realised in which mode?
Open the INSTRUMENTATION dataset. Search the dataset for variables that describe instrument, status and mode of the instrument. Display the information from the variables for household 3140813.
1use "${MY_IN_PATH}instrumentation.dta", clear
2list hid pid instrument status mode if hid==3140813

Household 3140813 was assigned to 4 different instruments, one of the persons answered the household (hh2) and a person questionnaire (pe2). Another person answered a person questionnaire and the third one answered a Pre-Teen questionnaire (s2-2). For an overview look at Paneldata.org (https://paneldata.org/soep-core/instruments/).
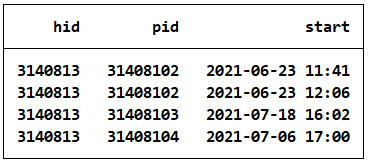
b) When did the household start their interviews? Did all members of the household start their interviews at the same day? Display the information from start for household 3140813.
1list hid pid start if hid==3140813
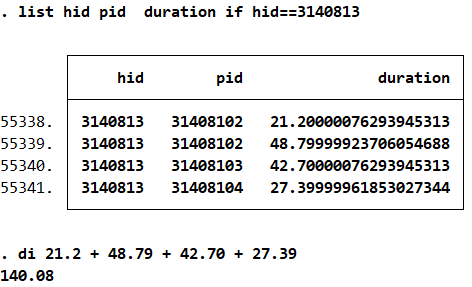
c) How much time was the household busy by their interview? Display the information from duration for household 3140813 and sum up.
1list hid pid duration if hid==3140813
2di 21.2 + 48.79 + 42.70 + 27.39
d) Where did the household members fullfill their interview? Display the information from location for household 3140813.
1list hid pid location if hid==3140813

Values for location are only -5 for this household. The value “-5” for the variable location stands for “Not included in this version of the questionnaire”. For more information on the values, see the Missing Conventions.
Information for location of the interview is only available for the CAWI mode.
1tab mode location,m

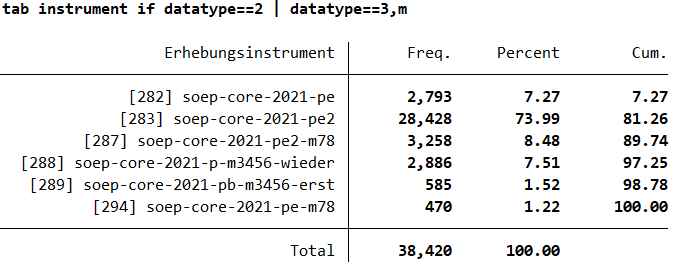
2. Which instruments go into the long dataset “pl”? Display the information from instrument for the dataset pl. Due to person-bio-questionnaires PL is part of datatype=2 and datatype=3.
1tab instrument if datatype==2 | datatype==3,m
3. How many households did the interviewer XX interview? HOw high was the proportion of households realized completely? Display the information from status for the interviewer 17.
1tab status if intid==17,m

The interviewer with the intid 17 try to interview respondents by 80 instruments. He was able to realise 65% of his instruments.
4. In which interview month in 2021 the respondents were mostly satisfied with thier lives (show only descriptive, no causalisation is asked for)? Information on the interviewyear is available in the instrumentation dataset. The variable concerning life satisfaction is typically asked in a person questionnaire. At first extract the month of the interview, then merge the instrumentation dataset to pl. Keep only the information for the survey year 2021.
At first we prepare pl and keep only information for the survey year 2021 and keep pid syear and the variable concerning life satisfaction: plh0182. The prepared dataset is saved as a tempfile.
1use "${MY_IN_PATH}pl.dta", clear
2keep if syear==2021
3codebook plh0182
4keep pid syear plh0182
5tempfile pl
6save `pl'
After that the instrumentation dataset is used to generate the interview month. Therefore we extract the month from the variable end “end of interview”. Variable end also include the date information for PAPI modes. The start of the interview is also available, but not for PAPI- interviews. The possible differences between start and end dates are ignored for this example. End is a string variable. One way to extract the month of the interview is to generate a variable idate as a double variable in a $td format, only include year, month and day of the interview. After built this variable the function month is used to get the month of the interview (imonth).
1use "${MY_IN_PATH}instrumentation.dta", clear
2codebook end
3gen double idate=date(end,"YMDhm")
4format idate %td
5gen imonth=month(idate)
To merge our prepared pl dataset to the instrumentation dataset the data pid and syear uniquely have to identify the dataset. PL is a dataset with information of the respondents. Thus we only need interviews which are realised (status=1) or which are disrupted (status=3). We only keep them.
1keep if inlist(status,1,3)
Our instrumentation is still not unique by pid and syear because there are also other interviews included, e.g. houshold interviews or youth interviews. That is why we look at datatype and keep only interviews which belong to “pl”.
1keep if inlist(datatype,2,3)
Now our prepared instrumentation dataset is ready for merging to pl.
1merge 1:1 pid syear using `pl'
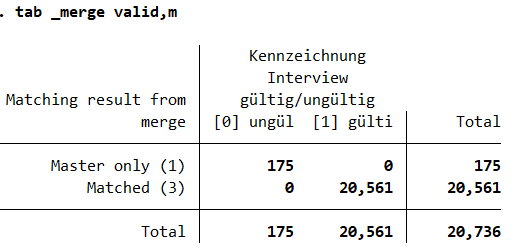
Some lines in instrumentation not merge with the pl dataset. The reason are unvalid instruments. We drop them.
1tab _merge valid,m
2drop if valid==0
After decode SOEP specific missings to general stata missings. We tab the interview month with the life satisfaction.
1mvdecode plh0182, mv(-2 -1)
2bysort imonth: sum plh0182
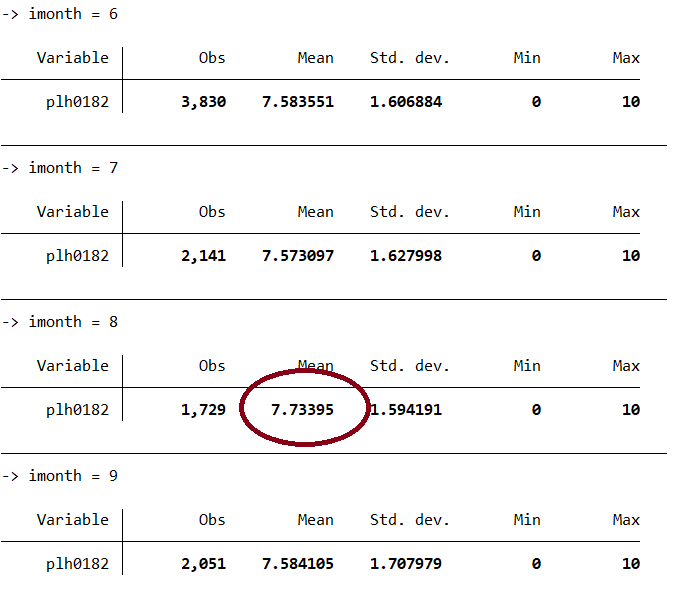
The respondents are mostly satisfied in 2021 in August, without any advice to causality.
Last change: Apr 07, 2026