Working with Migration Data (BIOIMMIG)¶
With its migration and refugee samples, SOEP provides a wide range of information on people with a history of migration or forced migration.
In the BIOIMMIG dataset, you will find relevant information on the history of migration or forced migration, including refugees’ and migrants’ motives for leaving their country of origin, their living conditions upon arrival in Germany, as well as information in edited form on any relatives in the country of origin and the desire to return to the country of origin. For more information about this dataset and a list of the variables it contains, see: BIOIMMIG Documentation.
In the following, we will use this record and other information from the SOEP to create a status variable that you can use to distinguish whether or not people with a migration background also have a background of forced migration, that is, whether migrants are also refugees.
Create an exercise path with four subfolders:

Example:
H:/material/exercises/do
H:/material/exercises/output
H:/material/exercises/temp
H:/material/exercises/log
These are used to store commands, log files, datasets, and temporary datasets. Open an empty do-file and define your paths with globals:
1***********************************************
2* Set relative paths to the working directory
3***********************************************
4global AVZ "H:/material/exercises"
5global MY_IN_PATH "//hume/rdc-prod/distribution/soep-core/soep.v37/eu/Stata/"
6global MY_DO_FILES "$AVZ/do/"
7global MY_LOG_OUT "$AVZ/log/"
8global MY_OUT_DATA "$AVZ/output/"
9global MY_OUT_TEMP "$AVZ/temp/"
The global “AVZ” defines the main path. The main paths are subdivided using the globals “MY_IN_PATH”, “MY_DO_FILES”, “MY_LOG_OUT”, “MY_OUT_DATA”, “MY_OUT_TEMP”. The global “MY_IN_PATH” contains the path to the data you ordered.
Task 1: Preperation of the Data
Use the Tracking Data PPATHL as a master file and merge the appropriate migration dataset. Open the record or browse the documentation and search for a variable describing the immigration status. The biimgrp variable from the BIOIMMIG data set is the appropriate variable.
1
2** Automatische Weiterscrollen aktiviert
3set more off
4
5***********************************************
6* Set relative paths to the working directory
7***********************************************
8global AVZ "H:\material"
9global MY_IN_PATH "Z:\DATA\soep33.1_de\stata"
10global MY_IN_PATH_long "$AVZ\Daten\SOEP32_long_10\"
11global MY_DO_FILES "$AVZ\do\"
12global MY_LOG_OUT "$AVZ\log\"
13global MY_OUT_DATA "$AVZ\output\"
14global MY_OUT_TEMP "$AVZ\temp\"
15
16
17*** Exercise 1 ******************************************************************
18
19/*
20a) Which variable contains information about the status of each person when they immigrated to Germany?
a) Which variable contains information about the status of each person when they immigrated to Germany?
Familiarize yourself with your variable and check the coding and case numbers.
1/*
Familiarize yourself with your variable and check the coding and case numbers.
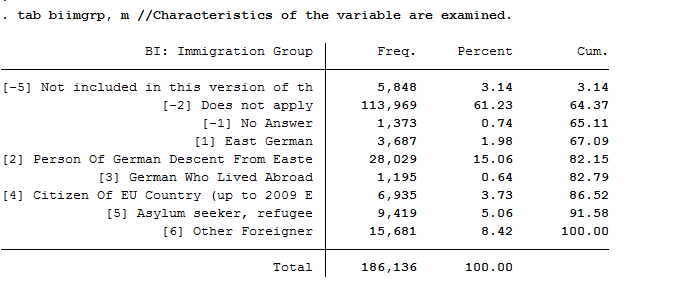
b) On the basis of this variable, generate the variable “escape”, which only distinguishes among three groups:
0 = Cases where no information is available
1 = All persons without escape background
2 = Asylum seekers / refugees
After you have familiarized yourself with the variable, recode it to fit your project. Then check the case numbers of your generated variable with the source variable.
1 Total | 63,755 100.00
2*/
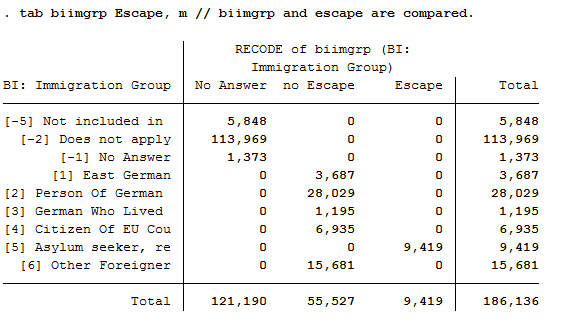
c) It may be that initially there is no information on the immigration status but this will change one year later. Limit the dataset to the last observation available on the respective person, since this gives you the most comprehensive information.
1
2*/
f) Save the generated data temporarily on your personal drive.
1f) Save the generated data record on your personal drive temporarily
2*/
3
4save $MY_OUT_TEMP\biimgrp.dta, replace
Task 2: Add basic variables from PPATH and weights
Attention
Please note that since version 34 (v34), PPFAD can be found in the subdirectory “Raw” of the data distribution file. The following exercises are done with version 33.1 (v33.1), where the tracking file was named PPFAD.
a) Load the following information from PPATH:
Permanent Indivdiual Identifier "persnr"
Household Identifier "hhnr" and the current household number "bghhnr"
The net variable with information about the interview type "bgnetto"
The gender of the person "sex"
The year of birth "gebjahr"
Variables on the migration background "migback" , "germborn" , "corigin" , "immiyear"
Information about the survey status: "psample"
If you want to familiarize yourself with the PPATH dataset, see the section Working with information on instruments (INSTRUMENTATION).
1/*
2a) Use the following information from PPFAD:
3 - Unchanging Person ID „persnr“
4 - Household number "hhnr" and the current household number "bghhnr".
5 - the net variable with information about the interview type "bgnetto".
6 - the gender of the person "sex"
7 - the year of birth "semester"
8 - Variables on the migration background "migback", "germborn" "corigin" "immiyear"
9 - Information about the survey status: "bgnetto" and "psample".
10*/
11
12use persnr hhnr bghhnr bgnetto psample sex gebjahr germborn corigin immiyear migback using $MY_IN_PATH\ppfad.dta, clear
b) Merge the previously generated data using the individual identifier.
If you don’t understand how to create your own cross-sectional dataset, see the chapter Generating a Cross-Sectional Dataset.
1/*
2b) Merge the previously generated data set using the person number.
3*/
4
5merge 1:1 persnr using $MY_OUT_TEMP\biimgrp.dta, nogen
c) Add the corresponding individual extrapolation factors to the data.
1c) Add the corresponding data using the individual identifier.
2*/
3
4merge 1:1 persnr using $MY_IN_PATH\phrf.dta, keepus(bgphrf) nogen
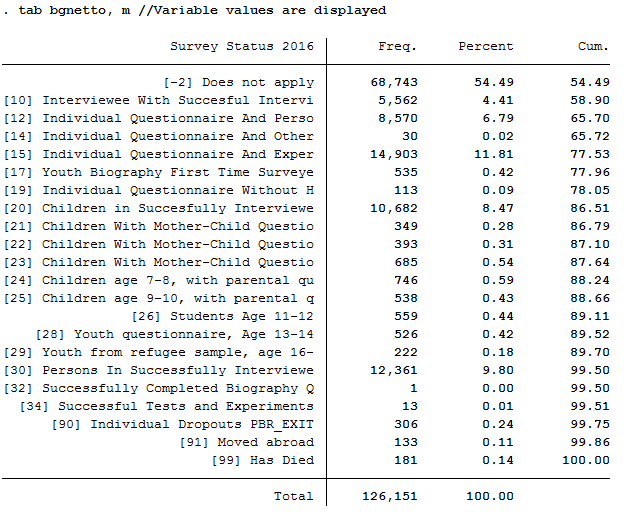
d) Only keep respondents who completed a youth or individual questionnaire in 2016.
For example, to exclude children who have not provided immigration status information, use the net code from PPATH. Only keep individuals who completed an individual or youth interview.
1/*
2d) Only keep respondents who completed a youth or individual questionnaire in 2016.
3*/
4
5tab bgnetto, m //Variable values are displayed
6
7keep if inrange(bgnetto, 10, 19) // People who have a code between 10 and 19 will be kept.
Task 3: Generate a status variable with the following categories:.
No migration background
Migrant, 2nd generation
Migrant, no information
Migrant, not refugee
Migrant, refugee
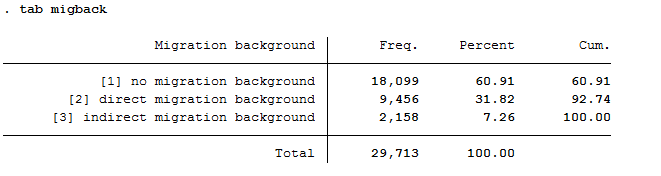
To generate this status variable, check the contents of the existing migration variables from PPATH (migback germborn).
1/*
2Generate a status variable with the following categories:
3*/
4
5tab migback
1tab germborn

Use the migration variables from PPATH (migback, germborn) and link this information with your previously generated refugee variable to build the described status variable from Task 3.
1gen Status = 0 // All persons will first receive the missing code for "no info".
2replace Status = 1 if migback == 1 & germborn == 1 // "no migback"
3replace Status = 2 if migback == 3 // "2nd generation" (2nd generation migrants born by definition in Germany, therefore "& germborn == 1" here unnecessary
4replace Status = 3 if germborn == 2 & Escape == 0 // "Immigrants without information"
5replace Status = 4 if germborn == 2 & Escape == 1 // "Immigrants, no escape"
6replace Status = 5 if germborn == 2 & Escape == 2 // "Immigrant, escape"
7
8label def Statuslbl 0"no info" 1"no migback" 2"2. Generation" 3"Immigrants without information" 4"Immigrants, no escape" 5"Immigrant, escape"
9label val Status Statuslbl // Values of the status veriable receive label
Task 4: Content analysis:
a) How many refugees (foreign-born with refugee/asylum status) are now in your file?
Look at your status variable previously generated in task 3 to answer the question.
1*** Exercise 4 ******************************************************************
2
3/*
4a) How many refugees (foreign-born with refugee/asylum status) are now in your file?
5*/
6
7tab Status, m //Display Generated Status Variable
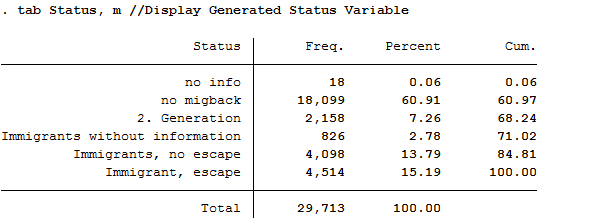
All 4,514 respondents who received the value 5 for the generated status variable have a direct migration background (migback==2), were not born in Germany (germborn==2), and fled their country of origin (flight==2 and biimgrp==5).
b) How many are there if you take the individual extrapolation factors into account? Interpret the results.
Look at the status variable generated in task 3 to answer the question.
1/*
2b) How many are there if you take the individual extrapolation factors into account? Interpret the results.
3*/
4
5tab Status [aw=bgphrf], m //Display generated status variable weighted with analytic weights
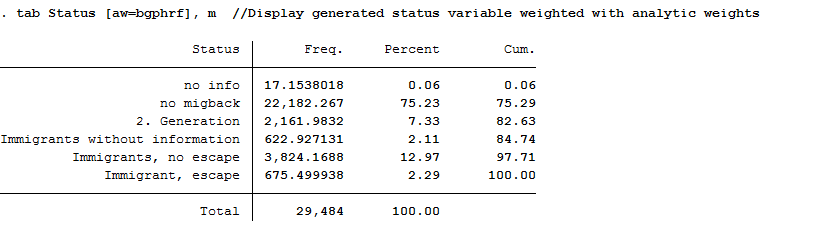
After weighting, there are approximately 675 refugees in the dataset. The weighting thus corrected the number of refugees downwards.
c) How many persons are represented in the sample, taking the extrapolation factors into account?
To use frequency weights in STATA, integer weights are required. Create an integer frequency weight from the weighting factor provided so that you can make representative statements. Then take a look at the new results.
1/*
2c) How many persons are represented when the sample taking the extrapolation factors into account?
3*/
4
5gen fweight = round(bgphrf) //Frequency weights for stata require integer weight
6tab Status [fw=fweight], m //Display generated status variable weighted with frequency weights
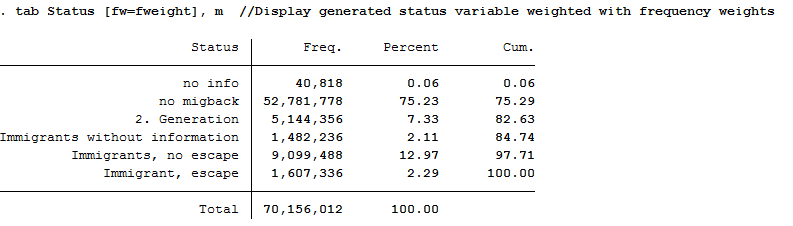
Around 1,600,000 people are represented.
d) What is the proportion of people over 40 years of age among the refugees?
Since the data in this exercise come from the wave “bg”, we are currently in the survey year 2016; if you need a description of the wave designations, please refer to the chapter Naming Convention of Data Sets and Variables. To generate a suitable age variable, you can use the year of birth (year of birth). If we look at the survey year 2016, all persons born in 1976 or earlier were over 40 years old. Generate a suitable age variable and look at the proportion of refugees over 40 years of age in weighted form:
1/*
2d) What is the proportion of people over 40 years of age among the refugees?
3*/
4
5gen ue_40 = 0
6replace ue_40 = 1 if gebjahr <= 1976 // Persons receive proficiency 1 if they were born before 1975.
7
8tab Status ue_40 [aw=bgphrf], m row nofreq
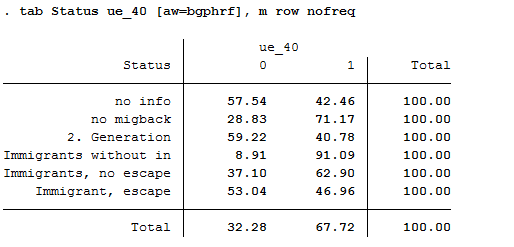
The proportion of refugees over 40 years of age is about 47%.
Last change: Apr 07, 2026